
Salesforce Flow Considerations

Hello,
Today we will talk a bit about Salesforce Flows. Probably you’ve heard some common opinions that Flows are great. As point-and-click automation, it allows you to build business logic faster and at a lower cost. I agree that Flow is an amazing automation tool that offers you a lot of possibilities! However, I don’t agree with the general emphasis on the Flows.
Before you use Flows in your project, you should be aware of their limitations and consider them alongside good old Apex!
Before we start
Before we proceed, we need to establish a few assumptions:
- Content below focuses on Record-Trigger Flow, not on the Screen Flow. We love Screen Flows!
- You should avoid many after Flows per object.
- Apex Triggers and Flows should be avoided on the same object.
And the most important:
❗️Flow is a powerful tool that can cover a lot of use cases.
❗️My goal is not to discourage you from using Flows – it’s more about knowing its limitations and weak points.
How many record-trigger flows per object?
It’s a complex topic. I’ve read numerous posts so you don’t have to.
- One Record Triggered Flow Per Object Per Type
- …Multiple Flows per Object is a Thing…
- One Big Record-Triggered Flow or Multiple?
- How Many Flows Per Object?
- How Many Flows Should You Have Per Object?
- Ever Wonder What is a Per Object – Per Type Record-Triggered Flow?
- Tom Hoffman’s ‘One Per Object’ Flow Design Pattern
- Record-Triggered Flow Design
The best choice in my opinion comes from Record-Triggered Flow Design:
- Before-Save Flows
Use as many before-save flows as you require.
You should, but do not have to, set Entry Conditions on your Flows.
Each Flow should be tied to a functional Domain, or a specific user story, as you see most logically. The order of the Flows in the Flow Trigger Explorer should not matter, as a single field should never be referenced in multiple before save flows as the target of an assignment or update. - After-Save Flows
Use one Flow for actions that should trigger without entry criteria, and orchestrate them with Decision elements.
Use one Flow to handle Email Sends if you have multiple email actions on the Object and need to orchestrate them.
Use as many additional flows as you require, as long as they are tied to unique Entry Criteria.
Set the Order of the Flows manually in the Flow Trigger Explorer to ensure you know how these elements chain together. Offload any computationally complex operation that doesn’t need to be done immediately to a scheduled path.
The concept of a single Flow per context is no longer the case.
Why do it this way?
Before-Save flows are very fast, generally have no impact on performance unless you do very weird stuff, and should be easy to maintain as long as you name them properly, even if you have multiple per object.
After-Save flows, while more powerful, require you to do another DML operation to commit anything you are modifying.
And even in Flow Best Practices documentation we can find that:
Because flows operate under Apex governor limits, the sky isn’t the limit. To avoid hitting those limits, we recommend bunching all your database changes together at the end of the flow, whether those changes create, update, or delete records. And avoid making edits in a loop path. Also, for smooth finish behavior, don’t create records before the first screen in the flow. You don’t want any CRUD operations running unintentionally.
One Automation Tool
Multiple times in the post, I mention that Apex Triggers and Flows should be avoided on the same object. Below, you will find why this is so important.
Best Practices for Designing Processes documentation mention:
If an object has one process, one Apex trigger, and three workflow rules, you can’t reliably predict the results of a record change.
Each time a record is created or updated, all record-change processes for its object are evaluated. We recommend restricting your org to one record-change process per object.
Have only one record-change process per object.
Why it is important?
- Consolidated View of Your Organization’s Object Automation – Storing all actions in a single automation tool can provide you with a clear understanding and predictability of the process. Utilizing numerous automation tools can lead to frequent invocations, as one automation process may call another and vice versa. Debugging record changes within such an environment is nearly impossible.
- Avoid Exceeding Limits – Flows operate within the boundaries of Apex governor limits. Many automation processes consume these common limits, which can increase the likelihood of reaching those limits.
- Determine the Sequence of Operations – When multiple processes that involve record changes are implemented for an object, Salesforce cannot guarantee the execution order. This can result in recurring invocations, where one automation process calls another and vice versa.
Consideration
Flows are not that easy
CASE
[…] So if you understand how Salesforce objects and fields work and interact with each other, you’re already halfway down the path to understanding flows. ~ Salesforce
[…] learning code takes more time and can often be more difficult, making people who code harder to find. Code-based projects are generally more expensive to build and maintain. ~ Salesforce
Salesforce narrative:
- Just drag & drop predefined elements.
- You don’t need developers.
Sounds amazing, but how is it in reality?
PROBLEM
Flows have a long list of best practices mentioned in The Ultimate Guide to Flow Best Practices and Standards and Flow Best Practices.
Here you can find some of them:
- Utilize subflows for cleaner, reusable, scalable ways to manage flows.
- Don’t overload flows with hard-coded logic.
- Add Null/Empty checks.
- Avoid excessive nested loops & ‘hacks’.
- Avoid looping over large data volumes.
- Check record and field security & flow context.
- Avoid data manipulation in a loop.
- Use fault paths.
- When using flows, keep flow limits and Apex governor limits in mind.
- Avoid mixing DML operations on setup objects, other Salesforce objects, and external objects in a transaction.
- You need to understand data types (String, Integer, Boolean) and collections (List).
And more…
Would a non-technical person understand it?
CONCLUSION
Of course, simple changes can be made by the person who understands business requirements. However, you need someone who truly knows Flows to do it right and who will follow the rules mentioned above. Salesforce mentioned about it on Flow Trailhead:
Flows are so powerful that you can think of them like visual coding. They’re created with clicks, not code, but you do need to understand some programming concepts and logic. ~ Salesforce
Flow is just visual programming, so all rules valid for standard coding apply to Flows.
Be careful with statements like "Flows are really simple", and "Flows can be used by anyone".
You need great admins and great developers who know how to build logic properly!
Huge flows
CASE
The new project, new requirements, and your tool: Flow Builder.
At the very beginning, your Flow is really small – just a few blocks.
With new requirements coming over, you end up adding more and more blocks to the flow.
PROBLEM
You end up with something like this:
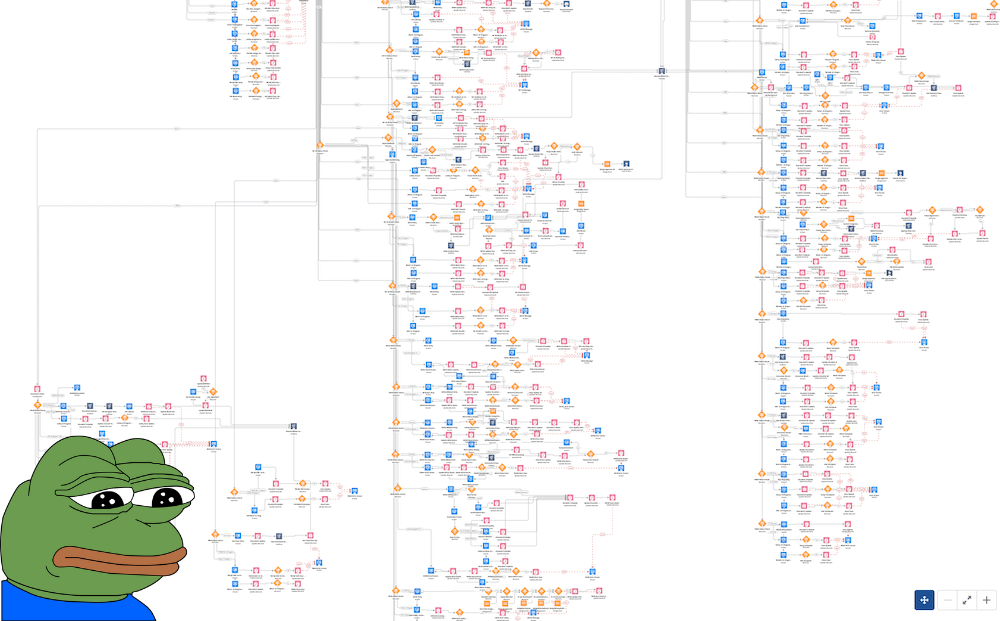
But wait, there are SubFlows; you can use them to make the code cleaner, reusable, and scalable.
Consideration:
- You can have only 2,000 active flows per type on the org. More SubFlows = Fewer Flows to build.
- It’s not as flexible as classes and methods. You cannot use Object-Oriented Programming to make code generic and reusable.
- Design Patterns – Can you use Design Patterns with Flows? Unfortunately no.
- As we read in The Ultimate Guide to Flow Best Practices and Standards SubFlows:
- Requires more collaboration and testing between groups if changes need to be made to the subflow.
- Debugging can be tricky with subflows. When you start using Lightning components and Apex actions, you don’t always get detailed errors if the error occurred in a subflow.
- There is some UX overhead associated with going overboard with SubFlows — don’t go making too many.
Another approach is to use Apex for complex processing.
It will be covered in the Complicated operations need Apex section.
CONCLUSION
The SubFlows can help you to deal with huge Flows.
However, it’s not a perfect tool and has some limitations.
The more complex project should use Apex instead of trying to build generic and reusable code with SubFlows (which is possible only partially).
Flows or Apex
CASE
[…] But by learning a few development concepts, you can use flows to do a lot of the same automation as code. ~ Salesforce
Automation created with declarative tools is usually easier to create and support. […] Code-based projects are generally more expensive to build and maintain. ~ Salesforce
Let’s extend a little bit the previous point about huge flows.
At the very beginning of a project, Flow will be a perfect approach. You need only an admin, which will apply requirements fast – Quick win.
PROBLEM
However, we should always think about projects in the long term.
- When new requirements appear, flows will be hard to manage and read.
- Not everything in Flows is possible (we will cover it in the next sections), so you need to use Apex Trigger/Invokable Apex as well.
- In Apex, you can use trigger frameworks, which allow you to separate trigger logic for each team. How to do it in Flows? SubFlow per team? What we can read in documentation: Because flows operate under Apex governor limits, the sky isn’t the limit. To avoid hitting those limits, we recommend bunching all your database changes together at the end of the flow, whether those changes create, update, or delete records.
- Entry criteria don’t support dynamic date field and RecordTypeName.
CONCLUSION
Before you choose Flow, think about the future of the project.
It will be really painful when you realize that you need Apex, because of Flow limitation.
What you can do?
- Keep Flows and use Apex Triggers = Nope, you should have one automation tool.
- Move everything from Flows to Apex Trigger = A lot of time = Costs.
- Flow + Apex Invocable methods = We will cover it in complicated operations need Apex.
It’s important to choose the proper tool carefully.
Starting with Flows and delegating complex logic to Apex make code hard to debug for administrators.
Not for Set and Maps
CASE
Business logic can be complex.
Collections like: List, Set, and Map are commonly used in Apex code to deal with data processing.Even more complex data structures, such as wrappers, can be created to work efficiently with the records.
PROBLEM
You CANNOT use Set or Map in Flows. Those basic data structures are not available to process records.
The only solution is to delegate the task to Invokable Apex. When only an administrator is working on the Flow, developing Invokable Apex can pose a challenge. This could potentially become a significant roadblock for the project without involvement from developers.
CONCLUSION
Flow is not the best choice when you need to deal with extensive data processing and transformation, which is a standard scenario in most projects. The only solution is to delegate the processing to Invokable Apex.
Not for complex SOQLs
CASE
Complex queries are commonly used in project’s code. It must have to meet client requirements. Clauses like COUNT, LIMIT, GROUP BY are standard in SOQL.
PROBLEM

Get Records block has limitations:
- There is no easy way to work on complex queries like:
- SubQueries
- Aggregations
- COUNT
- You cannot specify:
- LIMIT
- USING SCOPE
- GROUP BY
- You cannot execute some queries
with sharingand somewithout sharing. The context is the same for allGet Recordsblocks.
CONCLUSION
Loop, Decision, and Assignment blocks can help with data sorting and transformation. However, it takes many more steps to achieve the same goal as is done in Apex with just one line.
You cannot restrict the number of records you will retrieve with the Get Records block. It can lead you to Too many query rows: 50001 in orgs with a lot of data. It’s not a big problem? Schedule Flows used to process data in intervals can stop working because of it. On the other hand, Apex has batches that can process 50,000,000 records.
Complicated operations need Apex
CASE
Business logic can become more complex over time, and Flow limitations can prompt admins and developers to migrate certain parts of the Flow to Invokable Apex.
PROBLEM
Not everything in Flows is possible, especially when we are talking about complex operation like:
- Using Sets and Map
- Using complex SOQLs
- Processing large set of data
- also not all features are available in Flows
CONCLUSION
Flows limitation can be obtained by using Apex in weak points.
My thesis is: Using Invokable Apex in Flow is a kind of workaround for Flow limitation. It makes code more complex and harder to change or debug. Additionally, you need to prepare apex wrappers Requests and Results. Collect data in Flows that will be passed to the Apex. It’s not a perfect approach.
Simple problems
CASE
Business requirement: Update the counter (ContactsAmount__c) on the Account that tells you to have many contacts related to that account.
PROBLEM
Can you do it in Flow?
That flow limitation is related to Not for Set and Maps and Not for complex SOQLs.
Even really simple requirements can be difficult to do in Flows.
What if you figure out that it is not possible in Flows?
Will you create a trigger?
Record Trigger Flows + Apex Triggers on the same object = disaster.
Will you move everything to the Trigger?
It will take a lot of time – time is money!
CONCLUSION
As you can see even simple tasks can be difficult to complete in Flow.
Not for Large Set of Data
PROBLEM
Flow is not the best for High-Performance Batch Processing and Complex List Processing.
Flow’s formula engine sporadically exhibits poor performance when resolving extremely complex formulas.
Complex list processing, loading and transforming data from large numbers of records, looping over loops of loops. Common list-processing tasks, such as in-place data transforms, sorts, and filters, are overly cumbersome to achieve in Flow while being much more straightforward (and more performant) to achieve in Apex.
Lack of Feature
PROBLEM
- Transaction savepoints are not supported in Flow triggers and will likely never be supported in Flow.
Savepoint savePoint = Database.setSavepoint(); - Flow provides no way to either prevent DML operations from committing or to throw custom errors; the
addError()Apex method is not supported when executed from Flow via the Apex invocable method.
CONCLUSION
Salesforce invests a lot of money in Flows. Every release contains new Flow features.
The lack of addError() was my argument but! Allow customization of error messages for record-triggered flows will be delivered in Winter ’24!
Development
PROBLEM
What we can find in documentation:
-
Unexpected problems.
Sad to say, but sometimes a flow doesn’t perform an operation that you configured it to do. Perhaps the flow is missing crucial information, or the running user doesn’t have the required permissions.
-
Save your work.
Sometimes Flow Builder falls victim to unexpected problems, like losing Internet access. Salesforce doesn’t save your changes automatically, so it’s up to you to save your work.
CONCLUSION
Flow Builder has some issues. However, it doesn’t look like a big deal. Treat it more like a fun fact.
Code Scan Tools
CASE
When we think about mature code – we think about code scanner tools like:
Code scanning tools highlights potential issues that developers may want to address before continuing with the app-building process.
As we read in 8 Benefits of a Salesforce Code Scanner code scanning has advantages such as:
- Speeds Time to Market
- Reduces Technical Debt
- Improves Data Security
- Enables Other DevOps Tools
- Eliminates Surprises
- Increases Productivity
- Results in Better Products
- Complies with Data Security Regulations
PROBLEM
Can you scan Flows?
Not officially.
Code analysis tools often overlook Flows, allowing for implementations that might not be considered proper. Flow review currently requires manual intervention.
However, I have come across a few community-driven scanners:
While these are positive developments, without official support, there’s no assurance that they will cover all updates to Flows.
Many streams
CASE
There are a lot of Apex Trigger Frameworks that can help developers decouple business logic for each stream/team.
Each stream can have its own handlers that will be executed for specific entry criteria.
PROBLEM
How can you do it in Flow?
Based on How many record-trigger flows per object?. You can have before Flows as many as you need. The problem is with after Flows that should be limited and perform operations (DMLs) at the end of the Flow.
Let’s also jump to PR Review and PR Conflicts which is a bottleneck for different teams’ collaboration.
PR Review
CASE
Let’s take a look at Flow metadata.
Source: Flow.
<?xml version="1.0" encoding="UTF-8"?>
<Flow xmlns="http://soap.sforce.com/2006/04/metadata">
<actionCalls>
<name>Post_to_Contact_s_Feed</name>
<label>Post to Contact's Feed</label>
<locationX>269</locationX>
<locationY>396</locationY>
<actionName>chatterPost</actionName>
<actionType>chatterPost</actionType>
<connector>
<targetReference>Confirm</targetReference>
</connector>
<inputParameters>
<name>text</name>
<value>
<elementReference>chatterMessage</elementReference>
</value>
</inputParameters>
<inputParameters>
<name>subjectNameOrId</name>
<value>
<elementReference>contact.Id</elementReference>
</value>
</inputParameters>
<storeOutputAutomatically>true</storeOutputAutomatically>
</actionCalls>
<actionCalls>
<name>Get_Info</name>
<label>Get Info</label>
<locationX>372</locationX>
<locationY>354</locationY>
<actionName>GetFirstFromCollection</actionName>
<actionType>apex</actionType>
<dataTypeMappings>
<typeName>T__inputCollection</typeName>
<typeValue>Account</typeValue>
</dataTypeMappings>
<dataTypeMappings>
<typeName>U__outputMember</typeName>
<typeValue>Account</typeValue>
</dataTypeMappings>
<inputParameters>
<name>inputCollection</name>
<value>
<elementReference>accts</elementReference>
</value>
</inputParameters>
<storeOutputAutomatically>true</storeOutputAutomatically>
<assignments>
<name>Set_Contact_ID</name>
<label>Set Contact ID</label>
<locationX>568</locationX>
<locationY>396</locationY>
<assignmentItems>
<assignToReference>contact.Id</assignToReference>
<operator>Assign</operator>
<value>
<elementReference>existingId</elementReference>
</value>
</assignmentItems>
<connector>
<targetReference>Update_Contact</targetReference>
</connector>
</assignments>
....
</Flow>PROBLEM
A few issues exist here:
- How do review XML files?
- How much time do I need to spend to review it?
CONCLUSION
You need to log in to the environment and review Flow in Flow Builder.
Reviewing Flow in the development environment is a bad idea – so should you review it in the staging environment after the deployment?
Let’s be honest – review after deployment does not make sense.
There are also VSC Code plugins that help you review flows.
None of the above solutions are perfect and all require additional time and effort.
PR Conflicts
PROBLEM
PR Conflicts are related to PR Review and Many Streams.
Flows have a .xml structure, and because of it conflicts are almost not possible to resolve.
CONCLUSION
You need to deploy one version of Flow to the environment and resolve conflicts manually.
Try to such a situation by better communication with other teams.
Deployment
PROBLEM
When deploying flows to the Production org, you may encounter two problems:
- A requirement for 75% flow test coverage.
- Flows being deployed to Production as inactive by default.
CONCLUSION
This is a one-time action and is specific to Production. There is a slim chance that you will encounter this, but it’s still worth knowing. If you come across either of these two issues, you should navigate to Setup > Process Automation Settings and adjust the following two values:
- Set "Deploy processes and flows as active" to true.
- Set "Flow test coverage percentage" to 0%.
Unit Test
CASE
Code should be covered with unit tests.
Tests are as important to the health of a project as the production code is. Perhaps they are even more important because tests preserve and enhance the flexibility, maintainability, and reusability of the production code. So keep your tests constantly clean. Work to make them expressive and succinct. ~ Robert C. Martin "Clean Code"
You can write Unit Tests for your Flow!
PROBLEM
But…
- Code coverage is not required.
- Flow tests don’t support flows that run when a record is deleted.
- Flow tests don’t support flow paths that run asynchronously.
- Flow tests don’t count towards flow test coverage requirements.
- Flow tests are stored in
FlowTestmetadata. It means that tests will not run automatically on deployment.
Considerations for Testing Flows
Unit Tests should meet F.I.R.S.T. rules:
- Fast
- Independent
- Repeatable
- Self-Validating
- Timely
but how is it Independent and Repeatable when:
A flow test that verifies a date field is set to the relative date Today must be updated manually before running the test. For example, if you create and run the test on August 3, 2022, the date is set to the relative date: August 3, 2022. If you run the same test tomorrow, the date is still set to August 3, 2022.
CONCLUSION
Unit Test for Flows sounds like a great feature. For sure it is a step in the right direction, however, the tool is not perfect and does not meet the criteria of a "good" Unit Test.
Mathematics
PROBLEM
Apex offers more possibilities than Flow, and this is not a contentious assertion; it’s a logical fact.
Code is intended for humans, not machines. Apex, like any other high-level language, was created to simplify the lives of programmers. Assembler, a very low-level programming language, provides a multitude of possibilities and allows you to control numerous aspects. However, with increased possibilities comes higher complexity. Apex cannot perform as many functions as Assembler, but it is significantly more developer-friendly. This brings us to Flows – they are simpler compared to Apex, but they lack the same degree of flexibility.
In short:
Ease of use = Reduced flexibility, fewer possibilities.
Flow utilizes visual programming with predefined blocks, which offers several advantages:
- Low learning curve – You can start "coding" more swiftly without requiring an extensive grasp of object-oriented programming concepts.
- Flows are relatively straightforward – In contrast to Apex, you already have components that are easily comprehensible and usable. While the extensive capabilities of object-oriented programming are limited, having fewer possibilities translates to fewer decisions to make, thereby reducing the chances of errors.
CONCLUSION
Flows will NEVER match Apex’s multitude of possibilities. Why? If a Flow attempted to replicate all of Apex’s features, it would become excessively convoluted and sluggish. The benefits that Flow currently provides would dissipate. You cannot recreate everything you have in Apex; doing so would essentially replicate Apex itself.
Why should you never think in terms of what is better, Apex or Flow?
Greater ease of use, quicker development + fewer possibilities = Flow.
Less straightforward, more steps to develop + more possibilities = Apex.
Summary
Before we decide what to use, Apex or Flow, we need to understand the customer’s budget and project complexity.
Flows are great, but have some limitations like:
Flow’s formula engine sporadically exhibits poor performance when resolving extremely complex formulas. Complex list processing, loading and transforming data from large numbers of records, looping over loops of loops. Common list-processing tasks, such as in-place data transforms, sorts, and filters, are overly cumbersome to achieve in Flow while being much more straightforward (and more performant) to achieve in Apex.
More complex projects = more Apex.
| Budget | Complexity | Flow or Apex? |
|---|---|---|
| Small | Low | Flow |
| Small | High | Flow + Invokable Apex for crucial parts |
| Big | Low | Up to the client. Using Apex can be beneficial in the future |
| Big | High | Apex |
I am not a big fan of Record Trigger kind. In my opinion – in the long term – Flows can decrease the overall code quality of a platform by adding complexity. This complexity arises from the limitations that one must work within when using Flows. Software development is not an area where cutting corners to save money is advisable. Imagine constructing a house – you wouldn’t compromise on the quality of the foundation, and similarly, using proper tools in development is like building on a solid foundation.
On the other hand, I’ve encountered developers who love using Flows and have achieved great results with them on their projects.
It’s important to form your own opinion on this matter. Experiment with both Flows and Apex to determine which scenarios are best suited for Flows and which are better handled with Apex. Peace! ✌️
If you have some questions feel free to ask in the comment section below. 🙂
Was it helpful? Check out our other great posts here.

